Indicast Architecture Overview
Note: The high-level architecture overview information below has been released, either in marketing
material or described in patents.
The diagram below shows the high-level architectural components of the Indicast
service:

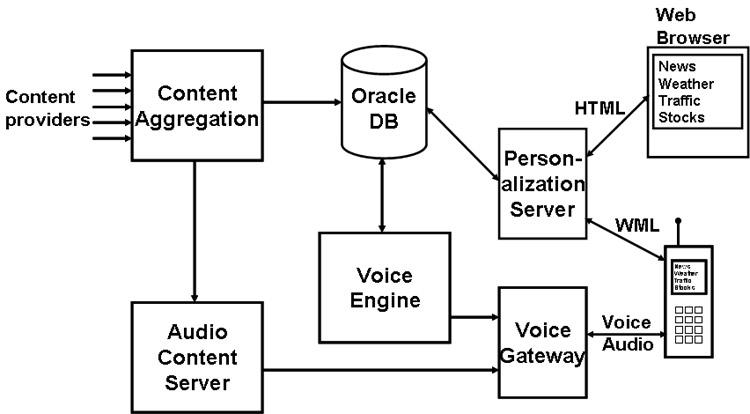
The Indicast architecture consists of three major areas: the Voice Engine and Audio
Content Server, which generates the user experience when calling Indicast, the Content
Aggregation system, and the Personalization Server.
Voice Engine
The Voice Engine Server is stateless, and therefore highly scalable and configurable
for high load balancing and for fault-tolerance. The state is managed by a
patented state language representing all state transitions and time stamps
during the call. This resides in the VoiceXML document, is updated during the call,
and is passed into the Voice Engine, which compiles it to determine the user's current
state. That current state, along with the last user response, is used to determine
the user's new state.
State Transition Definitions
The state transitions are driven from an XML that defines the entire user interface
for Indicast. This proprietary schema supports dynamic "grammar" (those commands
being listened for in a given state) and allows the entire user interface to be
redesigned without writing a single line of code.
Audio Content Server
All content is cached locally, both to reduce latency and to protect from temporary
provider outages. Depending upon the type of content, it is saved either in the
database or as audio files in the File Server. The Audio Content Server can provide
either pre-recorded audio to the Voice Gateway or it can generate concatenated speech
audio on-the-fly from data in the database.
Call History (from Voice Engine state language)
The state language has the additional purpose of maintaining a complete call history
of every voice command issued, story heard, etc. with timestamps attached to each.
Licensing of some content includes a revenue share agreement, and the call history
tells exactly what was played and for exactly how long, therefore minimizing content
costs.
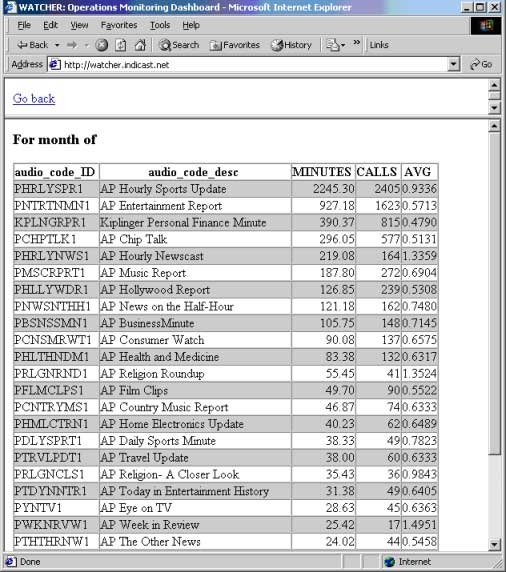
Content partners have access to their own secure Web site with play times broken
down by specific topic and by channel. This gives content partners incentive to
provide the best content, as they can see what's most popular, and their revenue
is tied to usage. Usage patterns show us and carrier customers what content is most
popular, and what is least, to help target content selections to the most popular
in a given region.
The state management also allows the user to be disconnected in the middle of a
call and then return to their current place in the content when they call back.
Voice command usage patterns show which commands are most used, and helps to pinpoint
problem areas where users are getting mis-recognitions, such as "I didn't understand."
or are saying something not in the "grammar" (those commands being listened for
in a given state).
Another plus of the state management is for systems that are advertising driven.
This advertising model was supported in Indicast's architecture since day one. Content
play history can be used to compile a profile of the user's preferred content types.
From that, targeted ads can be played that are quite relevant to the user's interests,
and consequently, advertising rates can be substantial. Also, voice "click through"
can be accomplished by saying a word relevant to the ad (such as "Say 'Amazon' to
hear more on a special offer from Amazon.com").
Content Aggregation
As mentioned above, all content is aggregated locally, and saved either in the database
or as audio files in the File Server. Conversion of the audio includes conversion
of audio format, sampling rate, etc. based on hand-optimized tests of each provider's
content. This is necessary because some content sounds best using one set of conversion
steps, and another sounds best with a different set of steps.
We normalize the audio level, both for the best user experience, and because normalized
audio levels improve speech recognition performance. We track updates of all content,
so that those who select on the Web site to hear "only new stories" will hear updated
content, but stories they have heard are skipped.
The content aggregation system is composed of a set of processes that are themselves
monitored by overseer processes that can stop and restart them if a problem occurs.
For instance, with the real-time sports scores streaming socket connection, we have
many layer of resiliency built in, so that we can switch to an alternate provider
socket and perform a number of other actions to resolve a provider problem. Each
step is logged, and notification is sent to Operations personnel if the problem
doesn't resolve itself quickly.
Operations can view the state of all content at any time. For instance, for the
Wall Street Journal content, we can see:
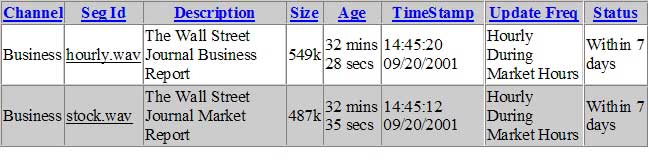
All content has a proper update frequency, and these are used to determine when
to generate notifications to Operations personnel.
Personalization and Preferences Server
An XML interface to the personalization engine is provided so that it remains independent
of the presentation layer. We provide a Java XSL engine and XSLT style sheets to
convert it to HTML for the Web site. This architecture has a number of advantages:
- All presentation information is isolated in the XSLT, allowing multiple brandings
and language versions to be supported on-the-fly.
- This method also supports other presentation markup.